vivo云服务照片视频批量下载代码~
起因,想要从vivo云服务中下载历史上传四五千张照片,结果点击全选之后,
居然要我一张一张下载,需要我不停的点保存,这就很抽象了,难道我想要的批量下载不应该是打包成压缩包或者直接批量下载到文件夹中嘛?
这点厂商做的甚至不如云盘,细节一点也没打磨!!!
第一步
打开vivo云服务官网,进入主页,打开控制台进行调试分析,进入相册,我们先刷新看看.
如图

图片1
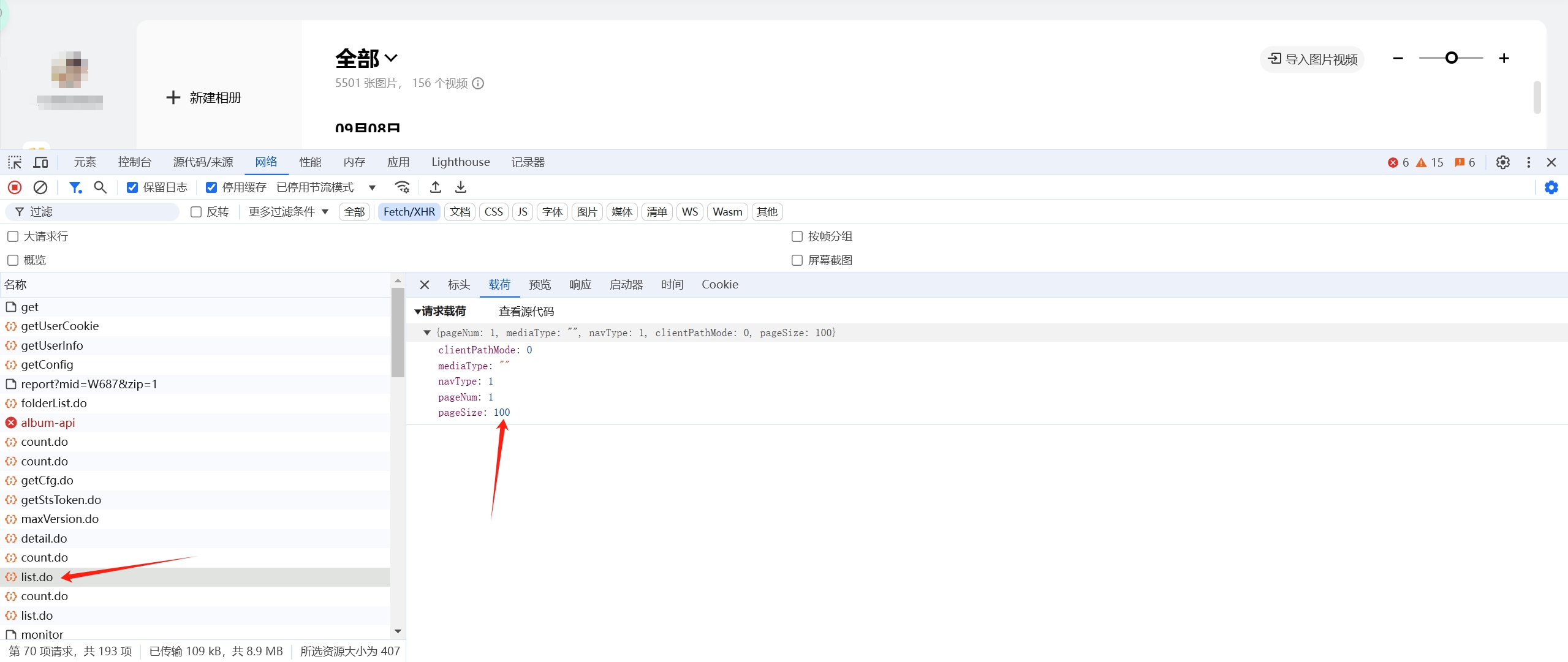
图片二
我们点进去看响应
{
"userId": "",
"metaId": "照片唯一ID",
"folderId": "",
"fileName": "照片名称",
"clientPath": "照片目录地址",
"clientPathAlias": "相机",
"clientPathMode": 1,
"clientBucketId": -1739773001,
"clientBucketDisplayName": "Camera",
"status": 2,
"mediaFormat": "image/jpeg",
"mediaType": 1,
"groupId": "0",
"groupType": 0,
"indexInGroup": 0,
"createTime": 时间,
"modifiedTime": 时间,
"duration": 0,
"width": 4032,
"height": 3024,
"clientCreateTime": 时间,
"totalSize": 3701187,
"orientation": 0,
"longitude": 126.545845,
"latitude": 45.855967,
"geoHash": "yb1uzegf",
"version": "172586734601588131",
"domain": "https://cloudalbum-cn09.vivo.com.cn",
"favorite": 0,
"clientSource": "0",
"extAttrMap": {
"clientDateAddTime": "时间",
"clientModifiedTime": "时间",
"mediaSpecialType": "0",
"imageHdrValue": "0"
}第二步
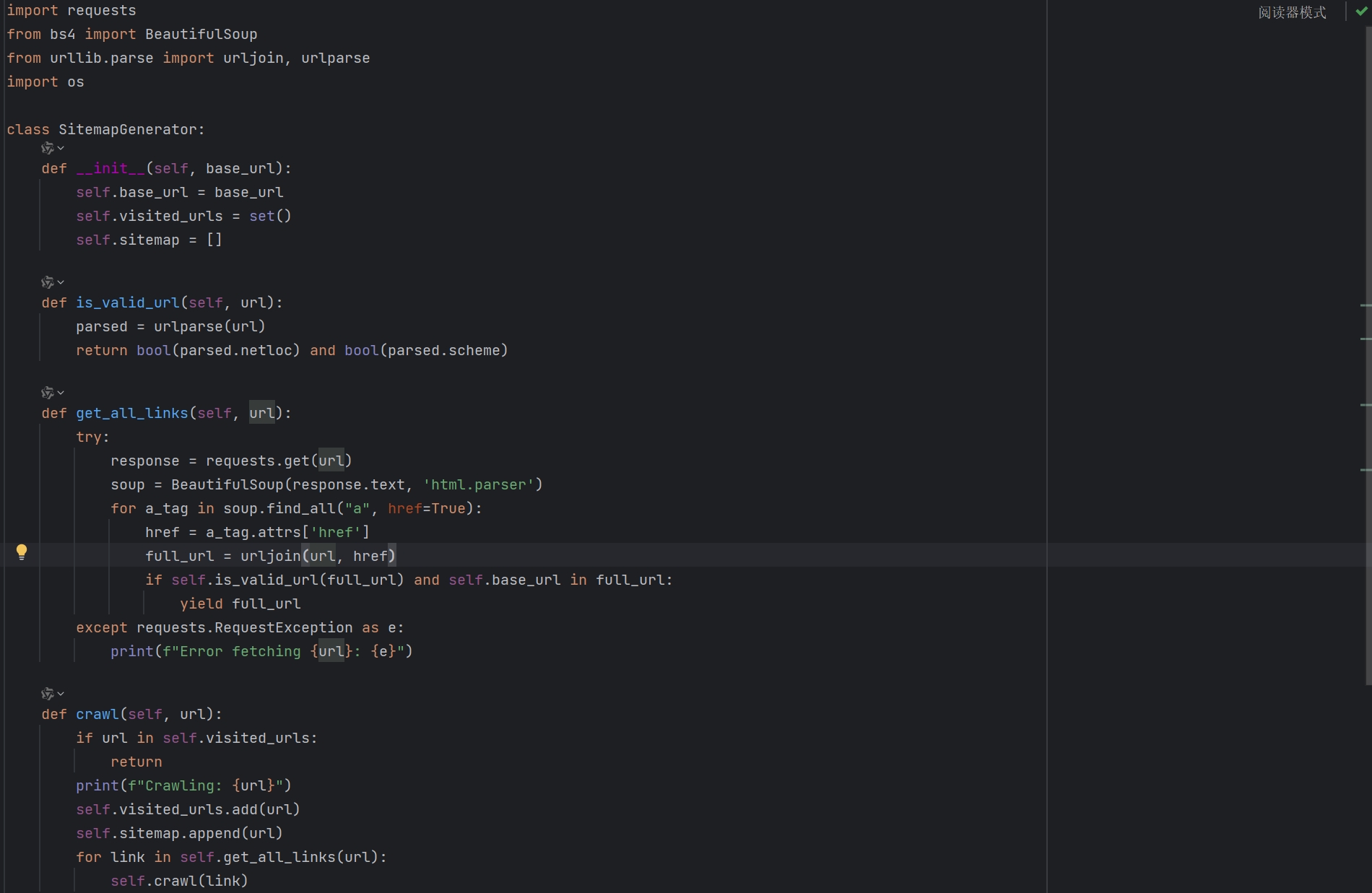
复制响应请求我们丢到python中,构造所需要的信息。一次性获取所有的返回数据然后筛选出所有的下载。

import http.client
import json
conn = http.client.HTTPSConnection("yun.vivo.com.cn")
payload = json.dumps({
"preCreateTime": None,
"preMetaId": None,
"pageSize": 10000,
"paths": [
"相机",
"视频"
],
"clientPathMode": 1
})
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'origin': 'https://yun.vivo.com.cn',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://yun.vivo.com.cn/',
'sec-ch-ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'x-yun-csrftoken': '自己去标头补全',
'Cookie': '自己去标头补全',
'content-type': 'application/json'
}
conn.request("POST", "/api/web/meta/list.do", payload, headers)
res = conn.getresponse()
data = res.read()
# 解析 JSON 数据
response_data = json.loads(data.decode("utf-8"))
# 提取并打印所有的 downloadUrl
if 'data' in response_data and 'fileList' in response_data['data']:
file_list = response_data['data']['fileList']
for file_info in file_list:
if 'downloadUrl' in file_info:
download_url = file_info['downloadUrl']
if not download_url.startswith('https://'):
download_url = 'https://' + download_url
print(download_url)
else:
print("未找到 fileList")补全信息后运行后输出如下
//cloudalbum-cn09.vivo.com.cn/api/file/download.do?metaId=xxxx //cloudalbum-cn09.vivo.com.cn/api/file/download.do?metaId=xxxx //cloudalbum-cn09.vivo.com.cn/api/file/download.do?metaId=xxxx //cloudalbum-cn09.vivo.com.cn/api/file/download.do?metaId=xxx
第三步
此时,我们去网页下载单个照片看看网页是如何构造的!
如图

请求url为 https://cloudalbum-cn09.vivo.com.cn/api/file/download.do?stsToken=xxxxxx&mode=0&metaId=xxxxx stsToken: 个人token mode: 0 metaId: xxxx图片唯一ID(第一个代码输出的)
将刚才保存的3.txt移到python目录下,然后我们构建批量下载代码
代码如下
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import os
# 读取 3.txt 文件中的 URL
with open('3.txt', 'r') as file:
urls = file.readlines()
# 参数
sts_token = "第三步请求载荷中的下载中的stsToken,一定是下载单个图片请求载荷中的stsToken"
# 创建 tupian 文件夹(如果不存在)
output_dir = 'tupian'
os.makedirs(output_dir, exist_ok=True)
# 自定义 headers
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Referer': 'https://yun.vivo.com.cn/',
'Sec-Fetch-Dest': 'iframe',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Cookie': '自己去标头补全'
}
def download_file(url):
url = url.strip() # 去除行末的换行符
if url: # 确保 URL 不为空
# 提取 metaId
meta_id = url.split('=')[-1]
# 拼接 stsToken 参数
full_url = f"https://cloudalbum-cn09.vivo.com.cn/api/file/download.do?metaId={meta_id}&stsToken={sts_token}"
try:
# 构建完整的文件路径
file_name = f"{meta_id}.jpg" # 统一为 .jpg 格式
file_path = os.path.join(output_dir, file_name)
# 检查文件是否已经存在
if os.path.exists(file_path):
print(f"文件已存在: {file_path}, 跳过下载")
return
# 发送 GET 请求下载文件
response = requests.get(full_url, headers=headers)
response.raise_for_status() # 检查请求是否成功
# 保存文件到本地
with open(file_path, 'wb') as f:
f.write(response.content)
print(f"下载完成: {file_path}")
except requests.exceptions.RequestException as e:
print(f"下载失败: {full_url}, 错误: {e}")
# 使用多线程下载文件
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_url = {executor.submit(download_file, url): url for url in urls}
for future in as_completed(future_to_url):
url = future_to_url[future]
try:
future.result()
except Exception as exc:
print(f"{url} 生成异常: {exc}")然后点击运行
效果图如下

1.如果第一次出现下载失败的请检查你的第三步下载单个图片中的请求载荷stsToken,一定是下载单个图片请求载荷中的stsToken填写对在进行尝试!!!!
2.如果是下载到一半失败了的话,请重新下载单个照片,然后再在浏览器控制台单个下载照片请求载荷中找到stsToken重新填写!!!
文章版权归王秋风公众号所有!
未经许可 不得转载、抄袭!